Western Digital Announces 22TB CMR and 26TB SMR HDDs: 10 Platters plus ePMR
by Ganesh T S on May 9, 2022 12:01 PM EST- Posted in
- Storage
- HDDs
- Western Digital
- SMR
- Ultrastar
- WD Red Pro
- WD Purple
- WD Gold
- CMR
- ePMR

Western Digital is announcing the sampling of its new 22TB CMR and 26TB SMR hard drives today at its What's Next Western Digital Event. As usual, the hyperscale cloud customers will get first dibs on these drives. The key takeaway from today's presentation is that Western Digital doesn't yet feel the need to bring heat-assisted magnetic recording (HAMR) into the picture. In fact, WD is doubling down on energy-assisted PMR (ePMR) technology and OptiNAND (introduced first in the 20TB CMR drives). WD is also continuing to use the triple-stage actuator that it started shipping in the first half of 2020 in the new drives. It goes without saying that the new high-capacity drives are helium-filled (HelioSeal technology). The main change common to both drives is the shift to a 10-stack design.

The SMR drives are getting an added capacity boost, thanks to WD's new UltraSMR technology. This involves adoption of a new advanced error correction algorithm to go along with encoding of larger blocks. This allows improvement in the tracks-per-inch (TPI) metric, resulting in 2.6TB per platter. The new Ultrastar DC HC670 uses ten platters to provide 26TB of host-managed SMR storage for cloud service providers.
ArmorCache Technology
As part of the announcements, WD also provided additional details on the caching feature enabled by OptiNAND - ArmorCache. Last year's announcement was quite light in terms of actual performance numbers, but the 20TB OptiNAND drives have been out in the market for a few quarters now.
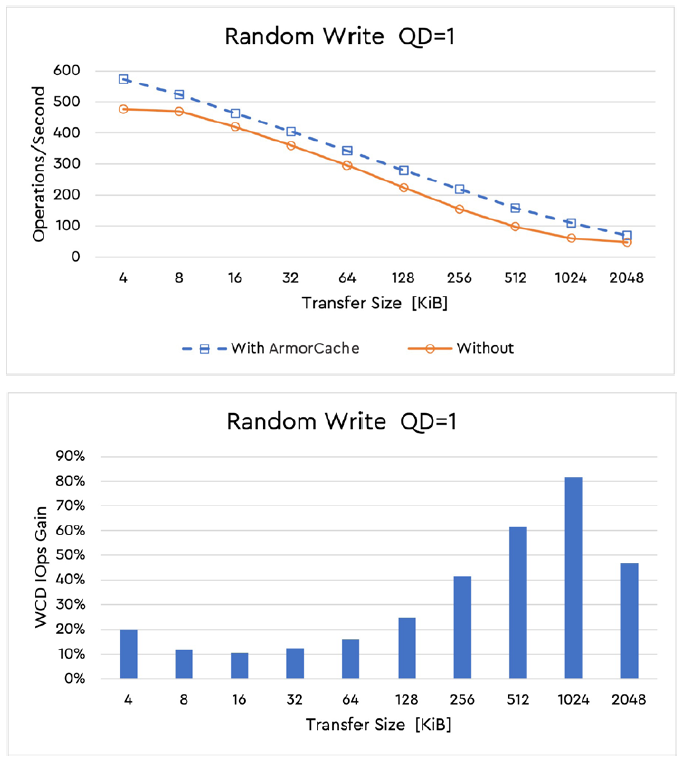
The UFS-based iNAND package helps the OptiNAND-based HDDs deliver upwards of 80% improvement in IOPS for low-queue depth large-sized random writes (10% - 20% improvement for small-sized writes) in use-cases where the write cache is disabled. Since non-OptiNAND HDDs can only cache whatever can be flushed out to the serial flash during emergency power-off situations, the larger cache size afforded by the iNAND device relaxes this limitation considerably. As discussed in the OptiNAND announcement coverage last year, use-cases with write caching enabled benefit from the EPO data protection afforded by the iNAND device. Enabling write caching often requires hosts to send out cache flush commands to the HDDs. These commands require the HDD to stop accepting new commands until the completion of the flush, resulting in loss of performance. The ArmorCache makes these flush commands unnecessary, allowing the drive to be used with full performance with no risk of data loss due to EPO.
Concluding Remarks
The 22TB Ultrastar DC HC570 and 26TB Ultrastar DC HC670 are currently sampling to hyperscalers. Volume shipment of the CMR drive to the channel is set for the next quarter. The Ultrastar HC HC670 is a host-managed SMR drive, and will hence ship only to select customers around the same timeframe. Western Digital will be delivering variants of the CMR drive across its HDD portfolio - 22TB WD Purple Pro for surveillance NVRs, WD Red Pro for NAS systems, and WD Gold for SMB and enterprise customers in summer.
The updated capacity points - in particular, the jump in the SMR drive capacity - delivers clear TCO benefits to WD's cloud customers. Crucially, WD believes it has enough trust in its ePMR setup to deliver 30TB+ HDDs without having to go the HAMR route. From a technology perspective, this will make the upcoming roadmap / product announcements from Seagate (HAMR deployment for publicly-available drives) and Toshiba (need for any technology beyond FC-MAMR) interesting to watch.








24 Comments
View All Comments
f00f - Monday, May 9, 2022 - link
In such schemes there is no empty spare drive. Instead there is distributed spare capacity reserved across all drives. This concept has been used for a decade or so.https://www.youtube.com/watch?v=nPAwq9uFTGg
Doug_S - Monday, May 9, 2022 - link
MUCH longer than a decade. HP's AutoRAID product did this nearly 30 years ago.phoenix_rizzen - Monday, May 9, 2022 - link
"Normal" RAID setup has X data disks and Y spare disks. The spare disks just sit there, empty, waiting to be used. When a data disk dies, the RAID array starts copying data to the spare disk. This is limited by the write IOps/throughput of the single spare disk. When you physically replace the dead drive and mark the new one as a spare, then it sits there idle until it's needed."Distributed spare" RAID setups (like draid on ZFS) has X data disks and Y spare disks. But, the "spare disk" isn't sitting there empty, it's actually used in the RAID array, and the "spare space" from that drive is spread across all the other drives in the array. When a data disk dies, the array starts writing data into the "spare disk" space. As this space is distributed across X data disks ... it's not limited in write IOps/throughput (it has the same IOps/throughput as the whole array). Once you physically replace the dead drive and mark the new one as the spare, then a background process runs to distribute data from the "spare space" onto the new drive (or something like that) to bring the array back up to optimal performance/redundancy/spares/
Think of it as the difference between RAID3 (separate parity disk) and RAID5 (distributed parity data). It's the different between a separate spare disk and distributed spare disk space across the array.
Read up on the draid vdev type for ZFS for more information on how one implementation for it works.
hescominsoon - Monday, May 9, 2022 - link
I do not use raidz 1,2,3. I use mirrored videos. When a disk fails you can copy the data from the mirror drive...which is much faster and less stressful than pounding the entire array of diskshescominsoon - Monday, May 9, 2022 - link
Vdevs not videos..sorry autocorrect got me.The Von Matrices - Tuesday, May 10, 2022 - link
Thanks for the explanation. So it doesn't solve the problem of slow rebuilds; it just enhances degraded array performance by making active use of disks that would otherwise be blank hot spares. It will still take ~1.5 days to write an entire 22TB replacement disk and reintroduce it to the array.tomatotree - Tuesday, May 10, 2022 - link
Depends on what you consider to be a problem about slow rebuilds. In terms of raw time to get the array back to the state it was before a disk died, there's no speedup and in fact probably it's a bit slower. But in terms of the time until you get back to full parity protection, where you can afford to have another disk die without data loss, the distributed rebuild scheme is dramatically faster.Drkrieger01 - Monday, May 9, 2022 - link
I built a CEPH cluster for an employer once... it's quite something to use. CEPH is one of these types of non-traditional RAID schemes, basically block storage distributed across multiple hosts. However, it suffers from a need of either many, many spindles, or a few high performance enterprise SSDs. It performs sync transfers, which pretty much bypass all the cache on the drives, so slowest possible speeds really. More spindles matter in this case!mode_13h - Tuesday, May 10, 2022 - link
Thanks for that post. I've long been intrigued by it. How long ago was this?I'm curious why you chose CEPH, rather than other options, like GlusterFS. It seems to a big disadvantage of CEPH is the amount of memory it requires (1 GB per TB of storage, IIRC).
mode_13h - Tuesday, May 10, 2022 - link
They ought to make an "Advanced SMR" or "ASMR" hard drive, that makes soothing, whisper-like noises during operation.