Arm Announces Armv9 Architecture: SVE2, Security, and the Next Decade
by Andrei Frumusanu on March 30, 2021 2:00 PM EST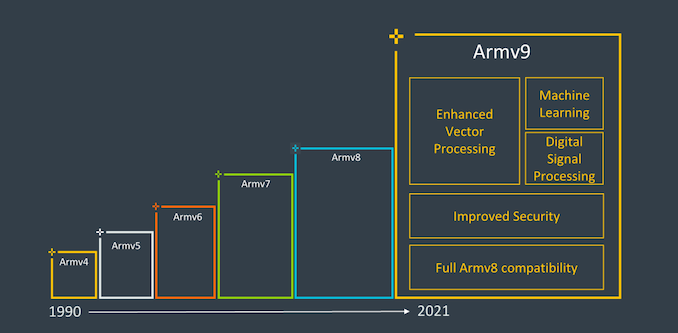
It’s been nearly 10 years since Arm had first announced the Armv8 architecture in October 2011, and it’s been a quite eventful decade of computing as the instruction set architecture saw increased adoption through the mobile space to the server space, and now starting to become common in the consumer devices market such as laptops and upcoming desktop machines. Throughout the years, Arm has evolved the ISA with various updates and extensions to the architecture, some important, some maybe glanced over easily.
Today, as part of Arm’s Vision Day event, the company is announcing the first details of the company’s new Armv9 architecture, setting the foundation for what Arm hopes to be the computing platform for the next 300 billion chips in the next decade.
The big question that readers will likely be asking themselves is what exactly differentiates Armv9 to Armv8 to warrant such a large jump in the ISA nomenclature. Truthfully, from a purely ISA standpoint, v9 probably isn’t an as fundamental jump as v8 was over v7, which had introduced a completely different execution mode and instruction set with AArch64, which had larger microarchitectural ramifications over AArch32 such as extended registers, 64-bit virtual address spaces and many more improvements.
Armv9 continues the usage of AArch64 as the baseline instruction set, however adds in a few very important extensions in its capabilities that warrants an increment in the architecture numbering, and probably allows Arm to also achieve a sort of software re-baselining of not only the new v9 features, but also the various v8 extensions we’ve seen released over the years.
The three new main pillars of Armv9 that Arm sees as the main goals of the new architecture are security, AI, and improved vector and DSP capabilities. Security is a very big topic for v9 and we’ll go into the new details of the new extensions and features into more depth in a bit, but getting DSP and AI features out of the way first should be straightforward.

Probably the biggest new feature that is promised with new Armv9 compatible CPUs that will be immediately visible to developers and users is the baselining of SVE2 as a successor to NEON.
Scalable Vector Extensions, or SVE, in its first implementation was announced back in 2016 and implemented for the first time in Fujitsu’s A64FX CPU cores, now powering the world’s #1 supercomputer Fukagu in Japan. The problem with SVE was that this first iteration of the new variable vector length SIMD instruction set was rather limited in scope, and aimed more at HPC workloads, missing many of the more versatile instructions which still were covered by NEON.
SVE2 was announced back in April 2019, and looked to solve this issue by complementing the new scalable SIMD instruction set with the needed instructions to serve more varied DSP-like workloads that currently still use NEON.
The benefit of SVE and SVE2 beyond addition various modern SIMD capabilities is in their variable vector size, ranging from 128b to 2048b, allowing variable 128b granularity of vectors, irrespective of what the actual hardware is running on. Purely from a view of vector processing and programming, it means that a software developer would only ever have to compile his code once, and if in the future a CPU would come out with say native 512b SIMD execution pipelines, the code would be able to already take advantage of the full width of the units. Similarly, the same code would be able to run on more conservative designs with a lower hardware execution width capability, which is important to Arm as they design CPUs from IoT, to mobile, to datacentres. It also does this all whilst remaining within the 32b encoding space of the Arm architecture, whereas alternative implementations such as on x86 have to add on new extensions and instructions depending on vector size.
Machine learning is also seen as an important part of Armv9 as Arm sees more and more ML workloads to become common place in the next years. Running ML workloads on dedicated accelerators naturally will still be a requirement for anything that is performance or power efficiency critical, however there still will be vast new adoption of smaller scope ML workloads that will run on CPUs.
Matrix multiplication instructions are key here and will represent an important step in seeing larger adoption across the ecosystem as being a baseline feature of v9 CPUs.
Generally, I see SVE2 as probably the most important factor that would warrant the jump to a v9 nomenclature as it’s a more definitive ISA feature that differentiates it from v8 CPUs in every-day usage, and that would warrant the software ecosystem to go and actually diverge from the existing v8 stack. That’s actually become quite a problem for Arm in the server space as the software ecosystem is still baselining software packages on v8.0, which unfortunately is missing the all-important v8.1 Large System Extensions.
Having the whole software ecosystem move forward and being able to assume new v9 hardware has the capability of the new architectural extensions would help push things ahead, and probably solve some of the current situation.
However v9 isn’t only about SVE2 and new instructions, it also has a very large focus on security, where we’ll be seeing some more radical changes.








74 Comments
View All Comments
SarahKerrigan - Tuesday, March 30, 2021 - link
Good to see SVE2 in base, though some of the choices being made by software projects around how to implement SVE have seemed a bit grody.CCA looks like TZ-rooted virtualization.
skavi - Tuesday, March 30, 2021 - link
Substantially more grody than typical SIMD? Any open source examples?SarahKerrigan - Tuesday, March 30, 2021 - link
Last time I looked at Eigen, IIRC, it was requiring a width to be specialized at compile-time... which kind of defeats the purpose. I only glanced over it briefly, so maybe I misunderstood.emn13 - Saturday, April 3, 2021 - link
It wouldn't surprise me that a compile-time specialized width is more efficient; part of eigen's extremely low overhead is that most of the decisions can be made compile time, and are often at least partially amenable to inlining, which in turn enables better compiler optimizations in general.Additionally, while it sounds great on paper that your vector size is flexible, I'm skeptical that the hardware will run as efficiently at it's true native sizes, as it would at larger sizes. It's quite possibly more efficient to target the true vector size for whatever operation you're running and in software schedule the iteration, because sometimes the algorithms involved are amenable to interleaving with other operations and/or other (more efficient) orderings. It's pretty difficult for the hardware to just guess what you're doing - in principle at least. But maybe ARM pulled it off; I'm just speculating here.
Finally, eigen is a pretty old project by now, with lots of in-depth optimizations for a whole bunch of algorithms and architectures. It's possible the code-base simply made common assumptions (namely fixed-size vectors) in so many places it's hard to change (though if "huge" sizes like 2048b had no additional overhead, why wouldn't eigen just target that?)
TL;DR: it might be a software design limitation, but it strikes me as at least as plausible that the flexible vector sizes still aren't as efficient as using the true vector size.
katiko - Thursday, April 1, 2021 - link
niceKangal - Thursday, April 1, 2021 - link
I know, I know, bu it has to be said though........what are the implications of ARM v9 in terms of other nations and companies?
In particularly, People's Republic of China, with their strong-arming of other companies and nations by using economic sanctions and mass media manipulation to get their way? This "trade war" has allowed us a glimpse of the ugly side of both super-powers. And things looks very questionable when probing into their nationalised-companies like Huawei and SMIC (in contrast to Cisco and Intel).
Will this (ARM v9) pave a way forward where China essentially misses out? Sort of like being forced to use a Snapdragon 805 (or Android 4.4), when your competitors are using the Snapdragon 820 (or Android 5.1). Key point in that analogy is the 64-bit support. Is that scenario good thing? Would that lead to China allowing for a proper unfiltered Internet? Or perhaps to China allowing foreign companies to their internal market? Does it matter? Or would it lead to nothing, except simply reduced competition in China and Global Markets?
vladx - Thursday, April 1, 2021 - link
Not gonna happen, ARM just recently announced it will continue to provide new SoC designs to Huawei.dotjaz - Friday, April 2, 2021 - link
What drugs are you on? Why would ARM get involved in this political mess? And why would ARM be able to force anything? You do realise cutting China off can only result in one thing, they euther abandon armv9 completely and turn to RISC-V or simply implement armv9 without a license, what you gonna do? Revoke their license?dotjaz - Friday, April 2, 2021 - link
In any case their strategy would be leaving ARM Ltd. behind, like they did with MIPS initially.Kangal - Saturday, April 3, 2021 - link
I doubt China would abandon crucial technology. I think they would rather seek out corruption in Companies and Governments, and gain access to the technology through alternative means. Or even more likely, they'd levarage their own infrastructure (or economy) as a tit-for-tat bargaining and gain official access through that way. Especially when knowing the short-sightedness of many politicians.